Datamining komt van de woorden ‘data’ en ‘mining’. Data is een term die al gauw om de hoek komt kijken en gaat over alle informatie die beschikbaar is. Veelal betreft het cijfers, maar het kan ook om andere vormen van informatie gaan, denk aan woorden en plaatjes. Het Engelse woord Mining gaat over het graven en delven. De term datamining gaat dan ook over het graven in grote hoeveelheden data om waardevolle patronen te herkennen en inzichten te verkrijgen. Let wel, het gaat niet om het verkrijgen van de data zelf maar juist om het verkrijgen van inzichten uit die data.
Technieken
Er zijn veel verschillende technieken die je helpen bij datamining. Hieronder vind je een selectie van veelgebruikte varianten:
- Classificeren: het rangschikken van data in groepen. Een voorbeeld kan zijn het indelen van klanttevredenheid over een product of dienst in de groepen laag, midden, hoog.
- Clusteren: hierbij deel je groepen in die eigenschappen met elkaar gemeen hebben. Wat kunnen we bijvoorbeeld zeggen over de gemiddelde levensverwachting van mannen ten opzichte van vrouwen? Hierbij maken we onderscheid in twee groepen en is er een significant verschil waarneembaar tussen de levensverwachting van beide groepen.
- Regressie: hierbij bepaal je welke variabelen van invloed zijn op een gekozen factor. Een voorbeeld hiervan is dat het aantal kilo’s dat je weegt afhankelijk is van het aantal calorieën dat je eet en het aantal dat je er verbrand.
- Patronen herkennen: welke patronen zijn er in verloop van tijd zichtbaar? Zo hebben wij bij Bureau Tromp bijvoorbeeld meer deelnemers die zich inschrijven in het voor- en najaar dan in de zomerperiode.
- Outlier-detectie: hoe verklaren we de (onverwachte) uitschieters in de dataset? De verkoop van broden in de buurtsuper is een bepaalde week sterk toegenomen. Nader onderzoek wijst uit dat de bakker om de hoek een week gesloten is waardoor klanten (tijdelijk) hun broden halen bij de supermarkt.
- Voorspellen: aan de hand van de bovenstaande technieken krijgen we ook handvatten om te voorspellen wat er gaat gebeuren. Als we zien dat er minder deelnemers zich inschrijven in juni en juli vanwege de zomervakantie, dan kunnen we daar volgend jaar ook rekening mee houden. Let wel, hierbij heb je altijd te maken met een foutmarge, met 100% zekerheid iets voorspellen is niet mogelijk.
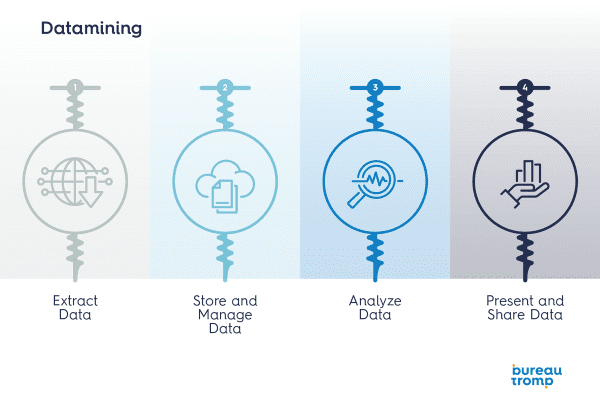
Hoe pas je datamining toe?
Om daadwerkelijk met een van bovenstaande technieken aan de slag te kunnen gaan op je eigen dataset, dien je nog een aantal voorbereidende stappen te nemen. Samenvattend ziet het proces van datamining er als volgt uit:
- Extract data: zorg ervoor dat je bruikbare data verzamelt door de juiste systemen te raadplegen en alle relevante informatie te verzamelen. Hierbij is het van belang dat data van een goede kwaliteit is en je ook de juiste interpretatie kent.
- Store and manage data: sla de data uit de voorgaande stap op in een voor analisten bruikbare database.
- Analyze data: nu kun je aan de slag met het analyseren van data. Maak gebruik van de hierboven beschreven technieken om relevante informatie uit de dataset te onttrekken.
- Present and share data: geef de data op een duidelijke en aantrekkelijke manier weer middels (simpele) visualisaties. De grootste uitdaging is om deze data zo te presenteren dat degenen die er iets mee kunnen het ook doorgronden.
Volg een datamining training bij Bureau Tromp
Dit artikel is slechts het topje van de ijsberg! Wil je meer weten over hoe je zelf met datamining aan de slag kan gaan, volg dan onze Process Mining training.
Ook interessant:
- Wat wordt er bedoeld met een normale verdeling?
- Wat is Six Sigma? Een duidelijk antwoord!
- DMAIC en Process Mining: hoe werkt het?